How It Works
Content moderation is hard, and — increasingly — platforms are looking to consensus-based models (e.g., the Facebook Oversight Board) that rely on expertise and local context input around edge cases. Models for community governance are also rare; however, those that exist can suffer from majoritarian dynamics. Harm is not equally distributed among communities as well; children, marginalized groups, historically-underrepresented minorities, and communities that have limited access to the internet may be disproportionately impacted. Input from communities needs to be representative of diverse views and values within and across communities, taking into account heterogeneity, power dynamics, and responsiveness to on-the-ground situations.
Further, inside companies, policy teams struggle to adjudicate edge cases, to improve policies based on defensible techniques, and to include local cultural values. Practically, it's also difficult to test policies and measure harm, because exposing people to problematic content is damaging and unethical, and experimenting in the Trust & Safety space can be complicit with introducing harm to communities or limiting exposure to successful interventions. Real-time updates of global policies and policy localizations are complex but critical, and red-teaming for policy teams is nowadays underdeveloped or non-existent.
The Undersight Board is a generative-AI policy testing system built on LLM-derived personas to allow policy managers, moderation leads, and operations teams to generate, test, and deploy localized community-specific inputs for Trust & Safety policy decision-making. We aim to develop a democratically-trained, model-assisted, and regionally-localized voice of the community system for policy inquiry, development, and evaluation.
We draw from contemporary research on community governance; memory-driven generative simulation; jury learning & deliberation; scalable opinion generation; and rich algorithmic co-design.
The purpose of the Undersight Board is to promote free expression by making simulated decisions regarding content on online platforms and by issuing recommendations on the relevant platform content policy, without exposing actual people to harmful content. Communities are represented by co-designing engineered prompts for LLM personas that best represent their local communities and contexts. These generative members will be empowered (literally, by electric current) to input perspectives into policy review and to provide scalable perspectives.
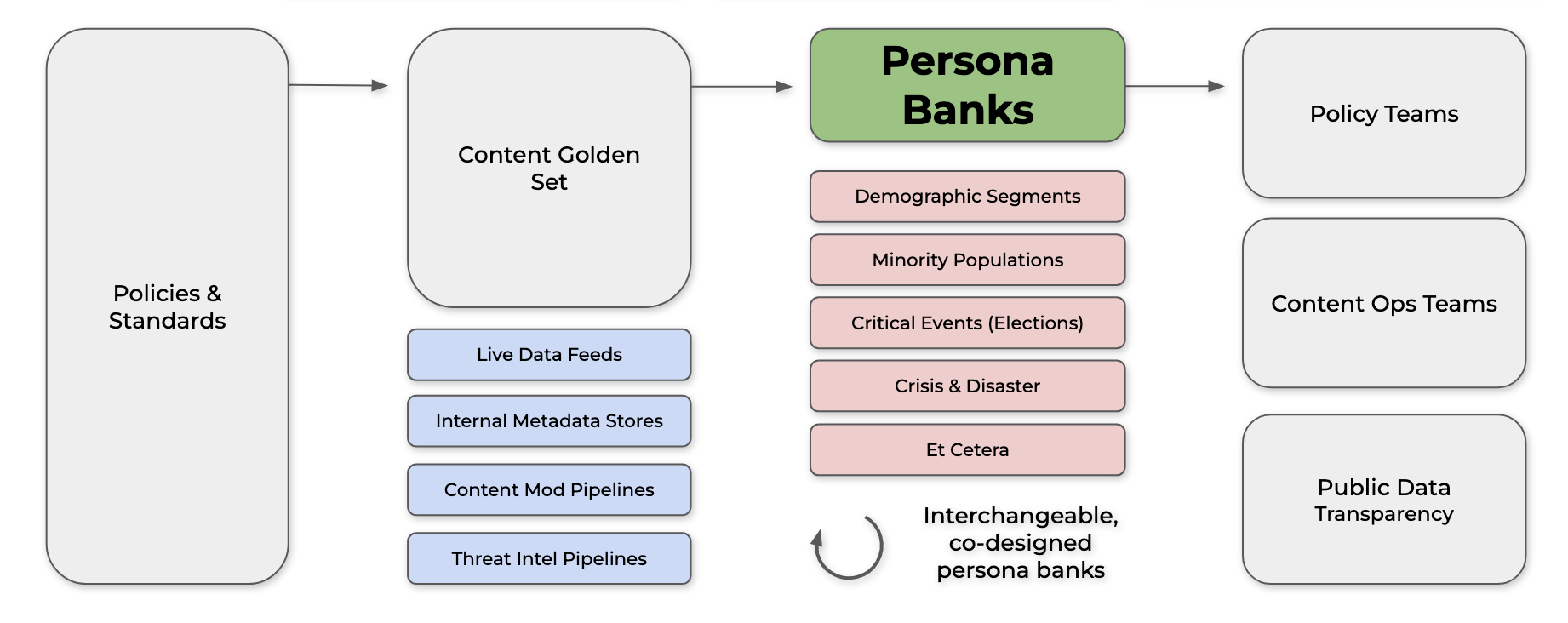
Based on a platform’s policies, they can generate a golden set of content moderation ground truth, or hook up the Undersight Board system to live or offline data feeds from your safety teams. Then, we prompt each piece of content across our persona banks, which are AI generated individuals co-designed with local community members. These persona banks house representative populations or demographically-weighted specific cohorts, the latter of which can be adapted to severe edge cases, like elections. The persona models will then generate key outputs, like perceptions of harm or other key outcome measures. These outputs are then passed to policy and operations teams, and they can also be made public for external validation.
When fully staffed, the Undersight Board will consist of thousands of interchangable "persona banks" from around the world that represent the most-globally-diverse set of disciplines and backgrounds – beyond any set of a few dozen experts. We're also considering key limitations of this system early and building with responsible innovation principles, covering topics like model and persona bias, community integration feedback models, and model exploitation and hijacking.